In this post, we will be learning different patterns in input regular expressions itself. With a slight change in delimitation, the below dataset is similar to the previous one.
Data
200 6459
CREATE TABLE sampleTab1(col1 string, col2 string)
ROW FORMAT SERDE ‘org.apache.hadoop.hive.serde2.RegexSerDe’
WITH SERDEPROPERTIES(
“input.regex”=”([^ ]*)\\s([^ ]*)”,
“output.format.string”=”%1$s %2$s”)
STORED AS TEXTFILE;
LOAD DATA LOCAL INPATH ‘Desktop/SpaceDelimter.txt’ INTO TABLE sampleTab1;

The explanation is also similar to the previous one. ^ is a symbol to signify that it’s the beginning of the line. The asterisk sign means zero or more characters. Now, [^ ] means that we are instructing Hive to start capturing the character by ignoring the space; this means that only one character is about to be captured. But the asterisk symbol instructs Hive to grab a string of zero or more characters. \s means that we’re asking Hive to overlook the space in between the strings.
Let’s see another pattern of regular expression.
CREATE TABLE sampleTab1(col1 string, col2 string)
ROW FORMAT SERDE ‘org.apache.hadoop.hive.serde2.RegexSerDe’
WITH SERDEPROPERTIES(
“input.regex”=”^(\\S+)\\s+(\\S+)$”,
“output.format.string”=”%1$s %2$s”)
STORED AS TEXTFILE;
LOAD DATA LOCAL INPATH ‘Desktop/SpaceDelimter.txt’ INTO TABLE sampleTab1;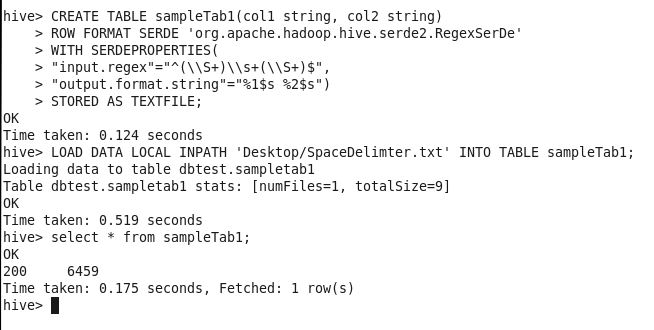
The ^ signifies beginning of the string and $ is to match the ending of the input string. The \\s (lowercase s) which is outside the brackets matches a whitespace. \\S+ (uppercase S) matches anything that is NOT matched by \s, i.e., non-whitespace. In regex, the uppercase metacharacter denotes the inverse of the lowercase counterpart.
In simple words,
> (\\S) fetches 200
> \\s ignores space because its outside of the brackets.
> (\\S) captures 6459
As stated in the previous post, it is a sample data and used only to demonstrate regex. We don’t need to use regular expressions if the data is in the same format. There are other techniques in Hive that help to transform the data into fields. Let’s check it out.
CREATE TABLE Test4(col1 INT, col2 INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘ ‘;
LOAD DATA LOCAL INPATH ‘Desktop/SpaceDelimter.txt’ INTO TABLE Test4;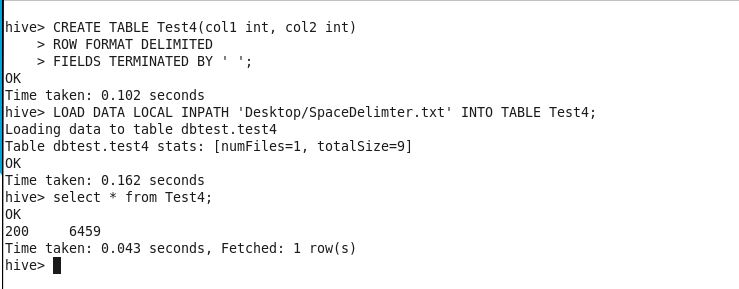
The above one is simple and straight forward, however there is another method.
SPLIT function:
CREATE TABLE Test2 (data string);
This table is just to hold the entire text data. No conversion and nothing, the entire line will be in a single column.
LOAD DATA LOCAL INPATH ‘Desktop/SpaceDelimter.txt’ INTO TABLE Test2;
Verify the data if it is loaded properly.
CREATE TABLE Test3(col1 INT, col2 INT);
This is the main table that gets loaded with the converted data.
INSERT INTO Test3
SELECT CAST(split(data,’\\ ‘)[0] AS INT),
CAST(split(data, ‘\\ ‘)[1] AS INT)
FROM Test2;
If you need more clarification, please do contact me.
In the upcoming articles we will discuss the regular expressions with more complex datasets and data with complex data types.
Stay in touch.

One comment