The Relational Database Architecture is the simplest model, since it does not need any complex structuring and does not entail complicated architectural processes. The simplicity of SQL, where even a beginner can learn to run basic queries in a short time, is a major part of the reason for the popularity of the relational model.
This is the reason we try to convert the complex and tedious data into structured format so that it’s easy to query and interpret data. Below is one of the complex data which we are going to convert into structured format in Hive.
Sample records from the dataset:
ReleaseYear MovieTitle
1969 Downhill Racer
1970 M*A*S*H
1970 The Party at Kitty and Stud’s
1970 Lovers and Other Strangers
1970 The Sidelong Glances of a Pigeon Kicker
1970 Hercules in New York
1971 Bananas
1971 Klute
1972 What’s Up, Doc?
1973 No Place to Hide
If you look at the data, there are two columns however it is difficult to convert these into structured format due to the delimitation. Thus, we depend on regular expressions again. Let’s see in how many methods we can convert it into columns in Hive.
METHOD-1:
–Let’s create the table with SERDE Properties.
CREATE TABLE movies2(movieYear int, movieTitle string)
ROW FORMAT SERDE ‘org.apache.hadoop.hive.serde2.RegexSerDe’
WITH SERDEPROPERTIES(
“input.regex”=”^(\\S+)\\s+(.*$)”,
“output.format.string”=”%1$s %2$s”);
— Loading the data
LOAD DATA LOCAL INPATH ‘Desktop/movies.csv’ INTO TABLE movies2;
Let’s query and see the results:
SELECT * FROM movies2;

METHOD-2:
–Let’s create the table with SERDE Properties.
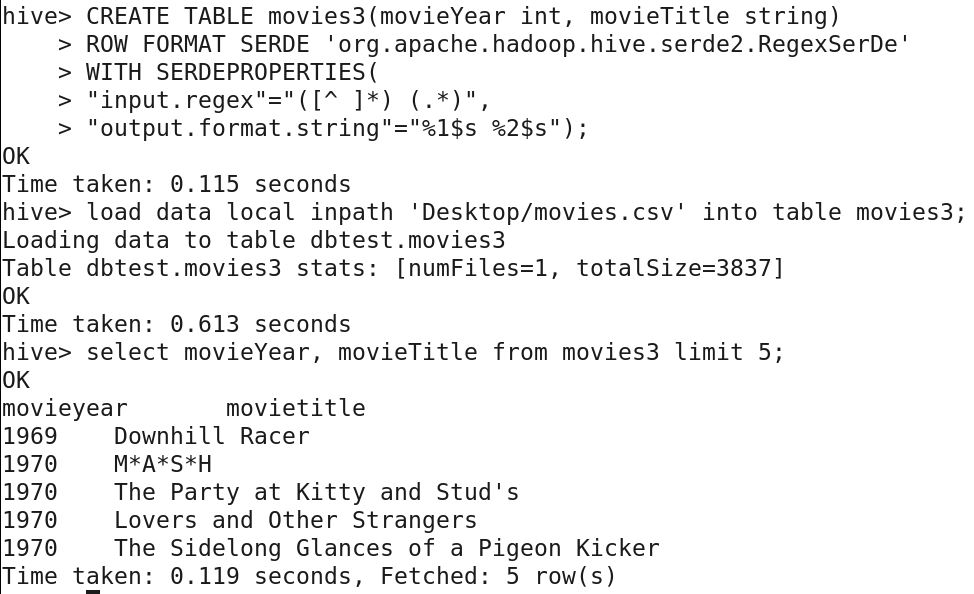
CREATE TABLE movies3(movieYear int, movieTitle string)
ROW FORMAT SERDE ‘org.apache.hadoop.hive.serde2.RegexSerDe’
WITH SERDEPROPERTIES(
“input.regex”=”([^ ]*) (.*)”,
“output.format.string”=”%1$s %2$s”);
— Loading the data
LOAD DATA LOCAL INPATH ‘Desktop/movies.csv’ INTO TABLE movies3;
Let’s query and see the results:
SELECT * FROM movies3;
METHOD-3:
We can convert the data using ‘REGEXP_EXTRACT’.
To learn more about this function, please click here.
–Let’s create dummy table to hold the entire data.
CREATE TABLE movies(data STRING);
— Loading the data
LOAD DATA LOCAL INPATH ‘Desktop/movies.csv’ INTO TABLE movies;
–Converting the data into meaningful columns.
SELECT REGEXP_EXTRACT(data, ‘^\\d+’, 0), REGEXP_EXTRACT(data, ‘\\s+(\\S.*)’, 1) FROM movies;

Explanation:
^\\d – matches the digit at the start of the string (^). + symbol represents one or more number of characters. Thus, it captures the first string from the beginning that has any number of digits.
\\s – Helps in skipping the space character. + symbol helps in skipping more than one space character.
\\S – Captures any non-whitespace char. And the dot and asterisk (.*) matches any zero or more chars other than line break chars. Index argument is 1 so that REGEXP_EXTRACT returns the captured group group without the initial whitespace.
Hope you find this article helpful.
Please click on the follow button to receive the notifications.

One comment