When I was asked to write something on ORDBMS, I thought it would be better to explain RDBMS first. While I am writing about RDBMS, I am thinking again of discussing about DBMS before I move to RDBMS. Hence, this article has become a bit lengthy but covers the core concepts of FMS, DBMS, RDBMS, OODBMS, and ORDBMS.
As you know databases are being used more than ever before to store and to access information. Due to the ease of maintenance and outstanding performance of databases, the growth of database technologies has been increasing rapidly. Moreover, DBMS had thrived over the World Wide Web. Different web-applications are retrieving the stored data and the answers are displayed in a formatted form using web languages like HTML. This article talks about the evolution of databases from the beginning and discusses their relative strengths and weaknesses.
File management system
Before the Database systems were introduced, data in software systems was stored in flat files. This type of system is called File Management System (FMS). This typical file-processing system is supported by a conventional operating system. The system stores permanent records in various files, and it needs different application programs to extract records from, and add records to, the appropriate files.
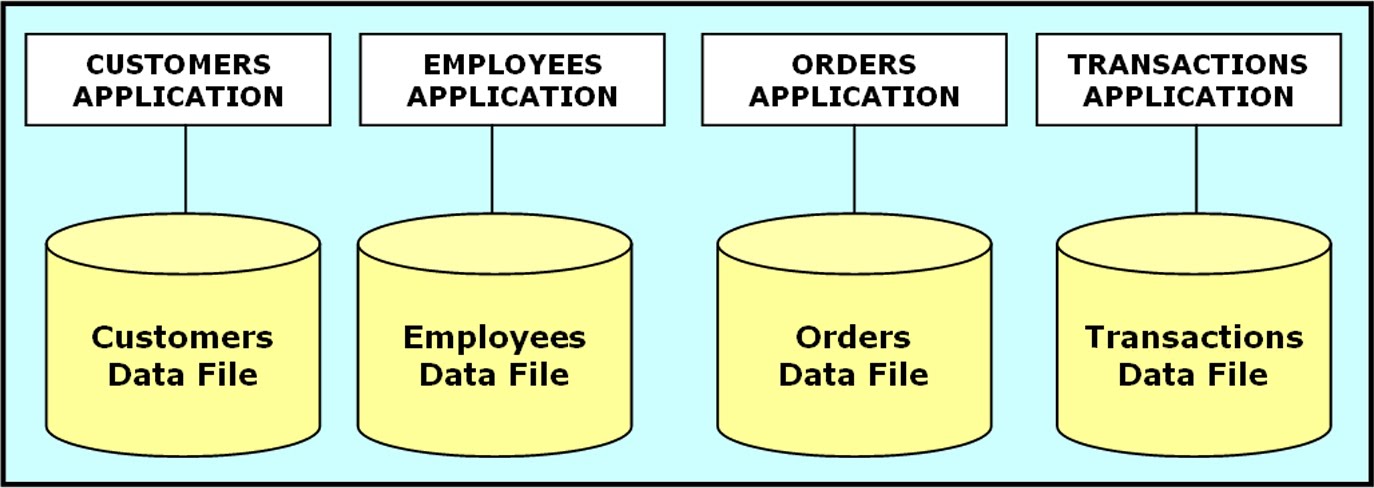
In a file-based system, different programs in the same application may be correlated or interact with different data files. There is no particular system enforcement and no relation between these data files.
Keeping organizational information in a file-processing system has a number of major disadvantages.
Data Redundancy and Inconsistency Assume that different users or programmers have written the application programs or created the files over a period of time. Probably the files have the same or different formats or the programs might be written in different languages. The same information may be duplicated in several files hence redundancy is introduced in the data. And if the data is redundant we can surely say the data is inconsistent as well. Different programmers access the same data simultaneously, and any modifications to the data might not be reflected in the data seen by the other.
Atomicity Problems:
Suppose, we were in the process of changing or inserting some data into the data files or somewhere else, and just then the computer system fails. It could be a power failure or some other known reasons for failure. What would one expect then? We should have the data in the same state as it was before the system failure occurred, right? This is called atomicity and it is difficult to ensure the same in a conventional file-processing system.
Security Problems
If we give authority on the entire database to all the users, then there may be a chance of security violation. Access to each user should be restricted to only certain data. But, in FMS, applying such security constraints is difficult.
Data Isolation
To retrieve particular data, what we really need is an application. The data may be in different files and files may be in different formats. Writing new application programs every time is a hectic issue and difficult.
Integrity Problems
We need to maintain particular rules in any application while storing the data. These are generally known as Integrity Constraints. In the FMS model, the data stored in data files won’t satisfy certain types of rules.
Unanticipated Queries
Through this conventional file-processing system we can’t retrieve data we need in an efficient manner. More responsive data-retrieval systems are required for general use.
Concurrent Access Anomalies
In large multi-user systems, multiple users may access the same file or record simultaneously. In FMS it is difficult to handle, and there is no way to find a particular record. Every search starts from the beginning of the file and examines each and every record in the file.
May be, handling the above issues are possible in a file-based system. The real issue was that, though all these are common issues of concern to any data-intensive application, each application had to handle all these problems on its own. In fact, all or some of the above problems can be handled by additional programming in each application. But writing an application for each task is time-consuming. The application programmer is burdened with not only implementing the application business rules but also with these other common issues.
DATABASE MANAGEMENT SYSTEM :
DBMS evolved when programmers were fed-up with FMS. The DBMS is a central system, which provides a common interface between the data and the various front-end programs in the application. It also provides a central location for the whole data in the application to reside.
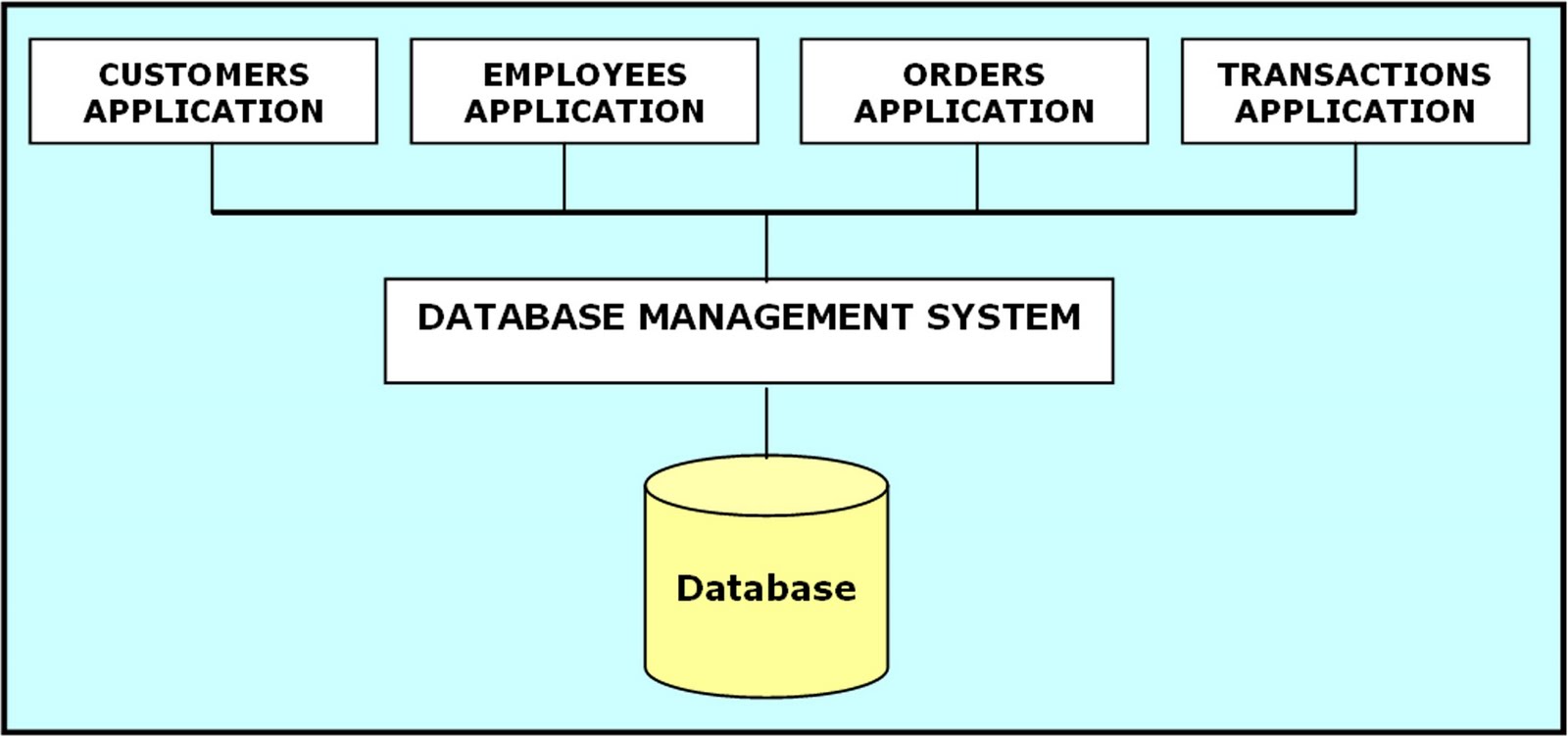
As we have already discussed that DBMS is having a centralized nature, the above picture illustrates the same. Applications are different, but the common data storage is the same. It overcame the limitations or disadvantages of FMS. What are they, let us discuss here.
Reduced Data Redundancy
Due to its centralized nature, the whole data will be stored in one database. So there is no chance of duplication or repetitive values. It is not possible for the data to be consistent all the way. There may be a chance of redundancy due to different reasons. May be, business or technical issues causes the data to be redundant to a certain extent. But we should be careful in controlling such redundancy to a large extent.
Data Consistency
If the data is not duplicated then we can surely say the data is consistent. Data consistency is possible only when data redundancy is reduced.
Data Integration
As we have discussed earlier, there should be some constraints in storing and accessing the data from the data file. It is possible in DBMS to give such type of integrity constraints, as all the related data is stored in one single database.
Data Sharing & Security
Data will be stored in a centralized way. So, the related data can be shared by single or multiple users. Security restrictions can also be applied.
Better Maintenance
As the data is stored in a centralized manner, we can control the data better and maintenance is also lesser and easier.
Well, the above said are to be considered as benefits when compared with the file management system. Because of these, DBMS became very popular and attracted large users in hardly anytime. Database Systems can be categorized according to the data structures and operators they present to the user.
(1) E-R Model
(2) Hierarchical Data Model
(3) Network Data Model
(4) Semi Structured Data Model
(5) Relational Data Model
(6) Object Oriented Data Model
(7) Object Relational Data Model
Among all data models mentioned here, relational model followed by object-oriented and object-relational models enjoyed most popularity. Let’s discuss these ones by one now.
RELATIONAL DATABASE MANAGEMENT SYSTEM
Dr. Edgar F. Codd, a research scholar invented the relational database concept in 1970 at IBM, which we refer to as RDBMS. This can be considered an extension of hierarchical and network models. He proposed certain rules to be qualified as a relational model, which are known as Codd’s rules.
In RDBMS, we do not have any parent-child relationships concept. All the data is in the form of simple columns and rows in a table. Each table is an individual and independent entity and we need not use any physical pointers or physical links to connect the entities like what we used to have in-network and hierarchical models. All data is maintained in the form of tables consisting of rows and columns. Data in two tables are related through common columns. Operators are provided for operating on rows in tables. Because of this, querying becomes very easy. This was one of the main reasons for the relational model to become more popular with programmers.
The difference between RDBMS and DBMS is, DBMS doesn’t support client-server architecture whereas RDBMS supports. Relationships between tables or files are maintained programmatically in a DBMS whereas the relationship between two tables is specified at the time of table creation. DBMS may satisfy less than 7 of Codd’s rules whereas, to be a relational model, more than 7 or 8 rules must be satisfied.
A sample project schema along with their relations are given below :
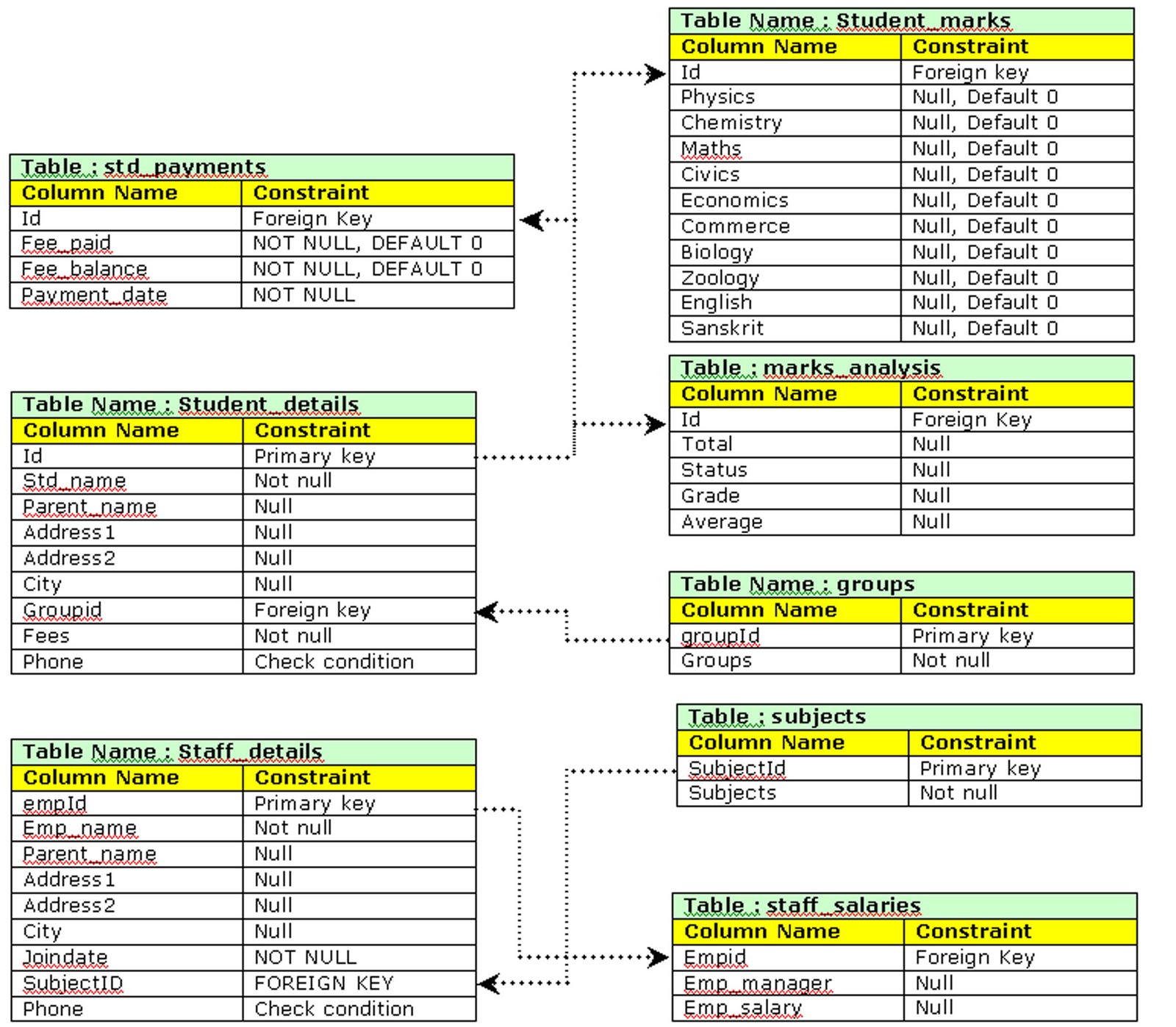
Benefits :
(1) In RDBMS system, the tables are simple, data is easier to understand and communicate with others.
(2) RDBMS are flexible, users do not have to use predefined keys to input information.
(3) Automatic optimization of searching is possible in RDBMS
(4) Structure Query language (SQL) is easier to learn and implement to satisfy the Codd’s rules.
(5) It supports large and very large databases.
(6) RDBMS are more productive because SQL is easier to learn. This allows users to spend more time inputting instead of learning.
Limitations
(1) Not much efficient and effective integrated support.
(2) Do not have enough storage area to handle data such as images, digital, and audio/video.
(3) Relational tables are flat and do not provide good support for nested structures, such as sets and arrays. And also certain kinds of relationships, such as sub-typing between database objects are hard to represent in this model.
(4) RDBMS technology did not take advantage of Object-oriented programming concepts, which is very popular because of its approach.
(5) All the data must be in the form of tables where relationships between entities are defined by values.
Well, to know the implementation of the relational model, please wait for some time to post the next articles, Schema Designs and Normalization will let you know how to create a schema and what we need to know before its creation.
OBJECT ORIENTED DATABASE MANAGEMENT SYSTEM (OODBMS) :
As you are aware, web and Internet usage is rapidly increasing nowadays. To meet the challenge of the web and to overcome the limitations of RDBMS, OODBMS was developed. OODBMS stands for Object-oriented database management system, which we can define as; it is a combination of Object-Oriented Programming and Relational Database Management System. Actually, RDBMS did not take advantage of Object-Oriented approach whereas it has gained widespread acceptance in the IT industry.
Providing consistent, data-independent and security is the main objective of the OODBMS, and also to control and extensible data management services to support the object-oriented model. In the relational model, we can’t handle big and complex data whereas in OODBMSs we can.
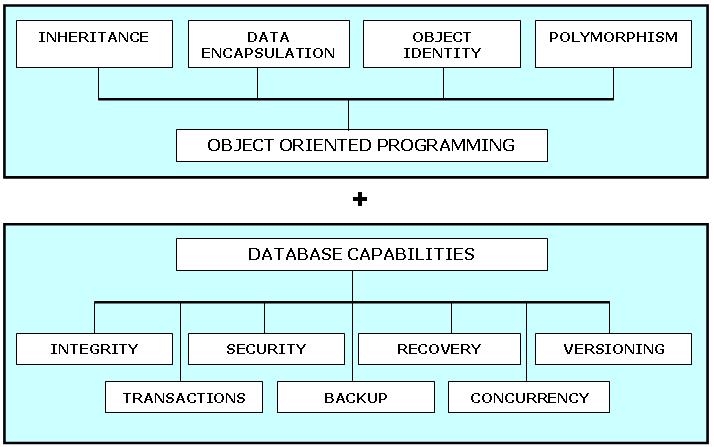
OODBMSs are well integrated and designed to work with complex C#, C++, and Java object models. OODBMS is actually meant for object storage and object sharing purpose and it is the solution for persistent data handling. It allows the storage of complex data structures that cannot be easily stored using traditional database technology.
Inheritances, data encapsulation, object identity, and polymorphism are the main characteristics of object-oriented programming. By defining new objects, we can develop solutions to complex problems in inheritance. Objects are related and shared within a network and have an independent identity. The object identity (OID) works behind the scenes to ensure the uniqueness of the tuples, which is invisible to the users. Moreover, no limitations are required on the values. If we take the same thing in RDBMS, then we have to worry about uniquely identifying tuples by their values and making sure that no two tuples have the same primary key values.
On the other hand, polymorphism and dynamic binding are useful to create objects to provide solutions to the complex ones and to avoid coding for every object. These objects may be transient or persistent. By persistent object, we mean the permanent object stored inside the database to survive the execution of data process and in order to eventually reuse it in another process. OODB deals with these objects in a uniform manner.
To create, update, delete, or to retrieve the persistent data, data definition language and data manipulation languages are important in OODBMS. These languages are also useful to define a database, including creating, altering, and dropping tables and to ensure the integrity constraints in tables.
When speaking of the differences between the relational data model and object-oriented data model, one should know that relationships between entities are defined by values in a relational model whereas in OODBMS relationships are represented explicitly. This is to improve the data access performance and to support navigational and associative access to data. In a relational model to access the data, we need a query language whereas in OODBMS the interaction with the database is done by transparently accessing objects. On one hand, this may be regarded as a drawback of OODBMS because the language is completely dependent, uses specific API and it is typical to access data.
OODBMS is undoubtedly a beneficiary system for those who require a low cost with the best performance in development, as it extends the language features with transparently persistent data, associative queries, data recovery, concurrency control, and other capabilities.
OODBMS has not yet received worldwide approval as it was considered to be in the developmental stages. The main disadvantages or limitations of OODBMS are, that there are no common data models, no current standard, and no strong theoretical framework and experiment activity.
OBJECT RELATIONAL DATABASE MANAGEMENT SYSTEM (ORDBMS) :
Object-Relational Database Management System (ORDBMS) is an extended development of the existing relational database system. To overcome certain limitations and to increase the performance level, and to achieve the benefits of the relational model and object model, ORDBMS technology evolved by combining the relational databases and object-oriented concepts.
We can incorporate our custom data types, functions, operators, and methods with the database and we can store images, geographical information, and multimedia objects such as audio and video in ORDBMS. And it allows us to raise the level of abstraction at which we want to view the problem domain.
ORDBMSs have extended functionality of DBMS and information system which can be deployed over different machines as it has a central server program whereas OODBMS has a typical distributed data architecture. This is the difference in architectures of ORDBMS and OODBMS. Another difference between ORDBMS and OODBMS is, an object-oriented database’s design is based solely on Object-Oriented Analysis and Design (OOAD) principles whereas ORDBMS is an extended development of the traditional relational database with object-oriented concepts structures such as abstract datatype, nested tables, and varying arrays.
In simple words, we can say that ORDBMSs synthesize the features of RDBMSs with the best ideas of OODBMSs.
Reference: Web, Books and Journals

One comment