As all (or most) of us know, SELECT DISTINCT eliminates duplicate records from the results and returns only unique values. But it’s very expensive in terms of resources consumption as it requires to sort or hash all rows over all columns in the table.
The use of DISTINCT might be pleasant until the column is a primary key & if the information is less. But the challenge is for huge data where tallying particular qualities can scale up to tens of millions and billions of cardinalities, and across terabytes and petabytes of information.
Apart from just counting, performing aggregation on numerous measurements along, consumes high resources and is real tough job for both traditional RDBMS and for Big Data technologies.
If you are wondering why it’s a problem for big data technologies like Hive or Impala while these are the technologies invented to handle such huge data!!
Hive queries invoke MapReduce and MapReduce executes the query using multiple Mappers and one reducer. Every map will send its results to the reducer thus reducer will always have more to process. Processing terabytes or petabytes of data is too expensive for the reduce method due to the high memory consumption as it all happens all in-memory.
There comes “Approximate Count of Distinct Values” into the picture.
While managing the large datasets, in case (1) if we do not need exact accuracy or (2) if approximate accuracy is acceptable or (3) if we are happy with the figures that may vary +/- 2% than the accurate figures and (4) if we are looking for a better method that is much less memory-intensive for the columns with high cardinality, then we can produce an estimate of the distinct values for a column using this method.
Let’s see what this method is in both traditional and big data technologies.
Impala:
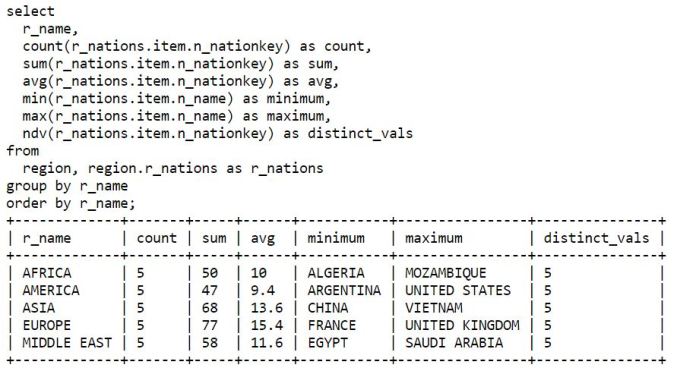
NDV (Number of Distinct Values) in Cloudera’s Impala is an aggregate function that returns an approximate value similar to SELECT DISTINCT.
This method is far plenty quicker than the aggregate of count and distinct and makes use of a steady amount of memory.
According to the Impala’s documentation the outcome is an estimate which might not reflect the precise number of different values in the column, especially if the cardinality is very low or very high. If the estimated number is higher than the number of rows in the table, Impala adjusts the value internally during query planning.
Example:
Oracle 12c:
APPROX_COUNT_DISTINCT is the function which returns approximate distinct values in Oracle SQL*Plus. Based on the documentation this function will return “negligible deviation from the exact result”.
1. SELECT COUNT(DISTINCT column) FROM Table1;
2. SELECT APPROX_COUNT_DISTINCT(column) FROM Table1;
The first query will return the exact or accurate figures and the second query returns an approximate figure. There is a difference in performance in both the queries; approx_count_distinct takes less time to return the results.
MongoDB:
As per the behavior specified in MongoDB documentation, db.collection. –estimatedDocumentCount() does not take a query filter and instead uses metadata to return the count for a collection. Thus, it is quicker than the countDocuments() which returns accurate information.
Examples:
1. countDocuments()
2. estimatedDocumentCount()
The names are self-explanatory. If we need accurate information, we need to use the first query and if we are okay with the estimation, we need to use the second one.
Update: The same functionality has been introduced in SQL Server 2019, for more information please click here.
Hope you find this article helpful.

5 comments