Data sampling is the best practice to understand the data patterns and trends of large datasets by looking at the smaller portion of the data instead of retrieving the large dataset. The main advantages of sampling are lower cost and faster data collection than measuring the entire huge dataset.
Often in RDBMS, we use LIMIT or TOP clauses in SELECT statements to pick up a few rows to understand the data. However these clauses are good to some degree where the amount of data is small. The disadvantage of the LIMIT or TOP clauses is that only the specified number of rows is returned from the result-set in a sequential order.
Here we’re going to explore different kinds of sampling techniques that are available in Apache Hive. Some of them are cost-effective and faster in response.
Row limit Sampling:
This is usual sampling method that we often use for smaller or medium level datasets.
SELECT registration_dttm as dttm, id, first_name FROM avro_sample
LIMIT 10;

As mentioned above, the limit clause only returns the specified number of records from the result-set and is in sequential order. Comparing to other sampling methods this consumes more resources.
Random Sampling
This should be used only If the requirement is to fetch random data.
SELECT registration_dttm as dttm, id, first_name FROM avro_sample
ORDER BY RAND()
LIMIT 10;

Through this method, the collection of data is random however it depends on mappers as well as on reducers hence it takes to time return the results.
Block Sampling
Through this method, Hive will return specified percentage data.
SELECT registration_dttm as dttm, id, first_name FROM avro_sample
TABLESAMPLE(20 PERCENT);
SELECT registration_dttm as dttm, id, first_name FROM avro_sample
TABLESAMPLE(10 ROWS);
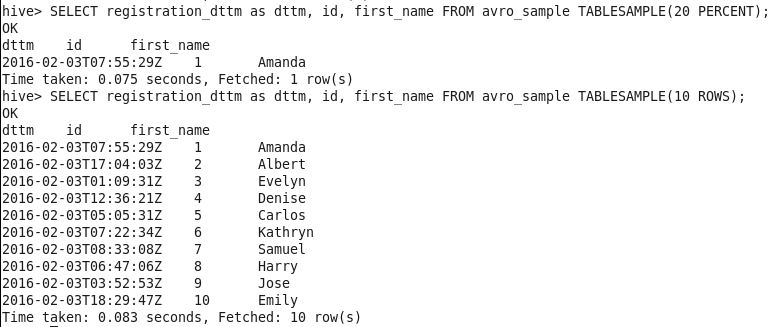
This returns the results very quickly, but it does not return random values.
Bucket Table Sampling
This is faster method among all for the huge datasets.
In this method, total volume of dataset splits into specified number of buckets and Hive picks random values from each bucket.
SELECT registration_dttm as dttm, id, first_name FROM avro_sample
TABLESAMPLE (BUCKET 1 OUT OF 50 ON RAND());
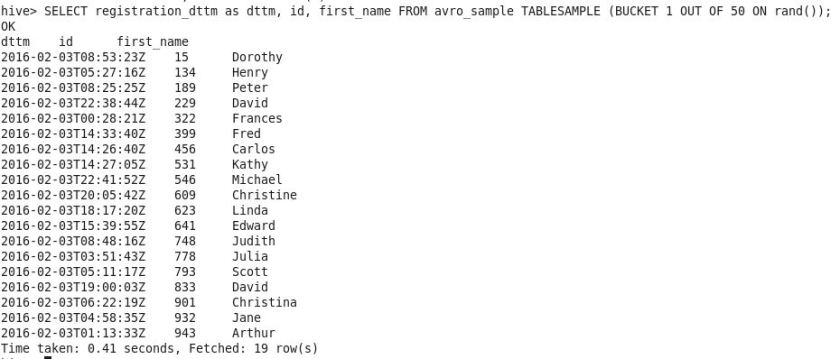
This method is optimized for bucket tables. On each execution, the above query will return different rows and also different number of rows.
Hope you find this article helpful.
Please do follow us to receive more interesting updates.

2 comments