Pig is a high-level scripting language used in Apache Hadoop. Pig allows to write dynamic data transformations without the awareness of Java. Pig’s basic SQL-like scripting language is called Pig Latin and appeals to developers already acquainted with SQL and scripting languages.
I’ll go through some of the key features regarding Apache Pig to help you understand it better. It’s a collection of information compiled from many sources.
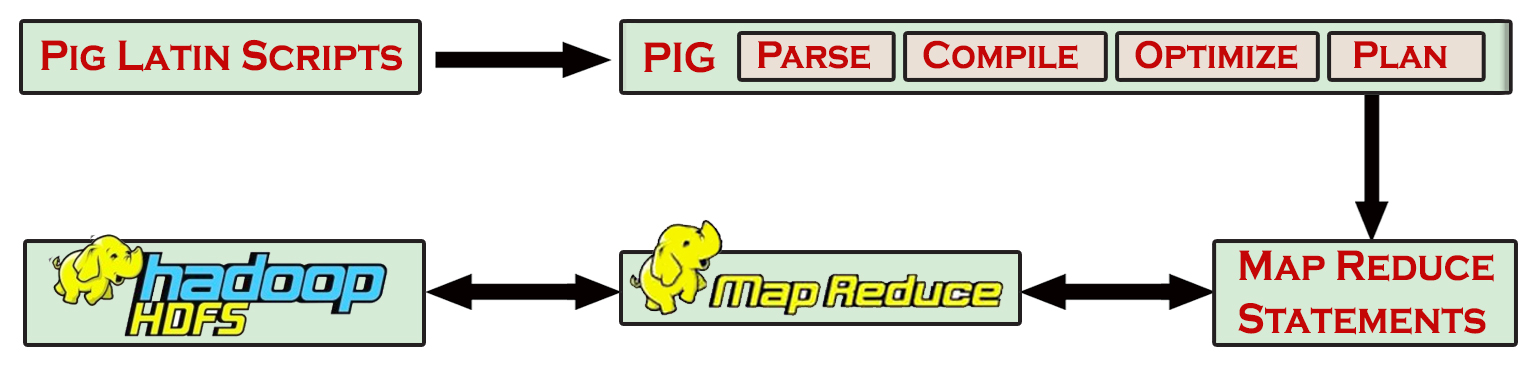
- For data analysis, scripts will be written in the Pig Latin language. Instead of being declarative like SQL, this language uses a step-by-step query structure that is more clearer and easier to write. Internally, all of these scripts are transformed to Map and Reduce tasks. Pig Engine is a component of Apache Pig that receives Pig Latin scripts as input and transforms them into MapReduce jobs.
- It needs extremely minimal lines of code as compared to Java. It employs a multi-query technique, resulting in shorter codes. If an operation in Java that takes hundreds of lines of code can be written in a few lines, development time is greatly reduced. It is said that the code is comparable to 200 lines of Java code in 10 lines.
- For reuse and contribution, the code can be saved in Pig Library / Piggy Bank.
- At any stage in the process, data can be saved. At run-time, schema and data types are defined lazily.
- Commands can be run in either interactive using the Grunt console or batch mode by submitting a script. Apache Pig can be connected in either local mode, which uses a local host and file system, or MapReduce mode, which uses a Hadoop cluster and HDFS.
- Many built-in operators in Apache Pig allow data operations such as joins, filters, and ordering. It also includes nested data types like as tuples, bags, and maps, which are not available in MapReduce.

Hope you find this article helpful.
Subscribing to this site will allow you to receive quick updates on future articles.

One comment