This post will show you how to use Cloudera’s Hadoop Distribution Quick Start VM to connect to Spark.
To enter Spark and work with it using Scala, type the following in the terminal.
[cloudera@quickstart ~]$ spark-shell

There are two points to discuss here. As you can see, one of the points is “Failed to obtain database default“. “SQL context is available as sqlContext“, says the second item.
Let’s talk about the issue in fetching ‘default’ database. This happens because Spark attempted to connect to the Hive metastore but was unable to do so. This could be due to a variety of factors, but first, check the hive-server and hive-metastore services. Starting these servers usually solves the problem.
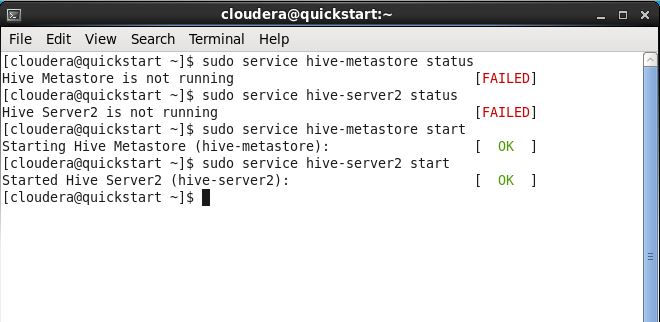
To verify the status of the services, open a terminal and type the commands below.
sudo service hive-metastore status
sudo service hive-server2 status
If the services are not running as shown in the image below, perform the commands below to start them.
sudo service hive-metastore start
sudo service hive-server2 start
Restart the Spark session at this point. Since the Spark session is currently operating on the default port, it will try to find the next available port if you open a new one.
Let’s move on to the second point about “SqlContext,” which is a class used to setup the Spark SQL functionality. The SparkContext class object (sc) is necessary for the SQLContext class object to be initiated.
The SparkContext is initialized using spark-shell with the line “spark-shell”.
Hope you find this article helpful.
Subscribing to this site will allow you to receive quick updates on future articles.
