Partitioning in Hive divides huge tables into smaller logical tables depending on column values; one logical table is created for each individual value. By defining the amount of buckets to produce, Bucketing in Hive divides the data into more manageable files.
Let’s have a look at how they differ from one another.
Partitioned Table:
Hadoop is often designed to handle massive datasets, thus tables will contain massive amounts of data. Partitioning is a method of organizing tables by dividing them into smaller portions based on partition keys, which are fundamental factors in defining how data is kept in the database.
Partitioning has the advantage of distributing execution load horizontally. There is a significant increase in performance while data retrieval since searching in data chunks is much faster than searching in the entire table.
Partitioning is a way of structuring tables by splitting them into smaller sections based on partition keys, which are crucial in determining how data is stored in the database. The tables that are partitioned called Partitioned tables.
Performance:
Hive partitioning is a good way to speed up queries on big tables. Under table location, partitioning allows you to store data in separate subdirectories. It significantly aids queries that use the partition key as a query parameter (s).

Pic: Partitioning in Hive.
Usage: Please click here to read more about partitioning and how to implement it.
Bucketed Tables:
By choosing the amount of buckets to create, Hive Bucketing/Clustering is a mechanism for splitting data into more manageable files. A user-defined number will hash the value of the bucketing column into buckets.
Performance:
When you use bucketing, you limit the number of buckets in which you can store your data. This value is set in the table creation scripts. Joins on the Map side will be faster because to the equal quantities of data in each partition.
Bucketing can be done with or without partitioning. The diagrams below demonstrate how bucketing divides the data.
1) Bucketed Table (Without Partitioning)

2) Bucketed Table With Partitioning

The following are the examples to create a bucketed table.
Bucketing can be done with or without partitioning. The diagrams below demonstrate how bucketing divides the data.
1) Bucketed Table (Without Partitioning)
2) Bucketed Table With Partitioning
The following are the examples to create a bucketed table.
Example-1:
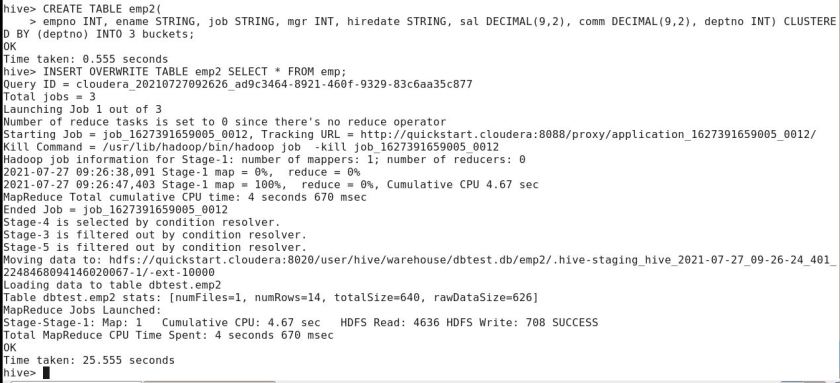
CREATE TABLE emp2(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate STRING,
sal DECIMAL(9,2),
comm DECIMAL(9,2),
deptno INT)
CLUSTERED BY (deptno) INTO 3 buckets;
SET hive.enforce.bucketing = true;
INSERT OVERWRITE TABLE emp2 SELECT * FROM emp;
Example2:
CREATE TABLE tblCustomerDetails(
CustFirstName STRING,
CustLastName STRING,
Address STRING,
City STRING,
State STRING,
Zip STRING,
MobileNumber STRING)
PARTITIONED BY (Country STRING)
CLUSTERED BY (State) SORTED BY (City) INTO 50 BUCKETS;
The table above is divided by country, as you can see. Then there’s the sub-division “State.” Unlike partitioned columns, bucketed columns are part of the table definitions.
Since the LOAD DATA command will not function for the above-mentioned tables, Hive should have a staging table where the INSERT INTO query can be used.
Hope you find this article helpful.
Please subscribe for more interesting updates.
