Apache Pig is a high-level framework for developing Hadoop-based apps. Pig Latin is the name of the platform’s language. Pig’s Hadoop jobs can be run in MapReduce, Apache Tez, or Apache Spark. Pig Scripting is used to explore huge datasets. It provides support for ad-hoc queries across big data collections.
In this article, we will be discussing the data model of Apache Pig.
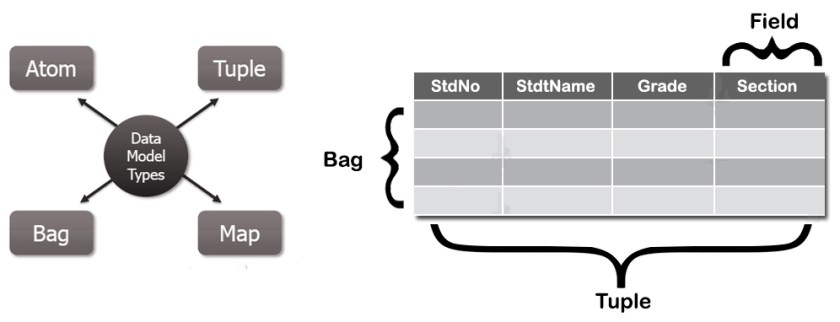
The four types of data models in Apache Pig are as follows:
- Atom:
An atomic data value that can be stored as a string. This model’s key feature is that it can be used as both a number and a string. - Tuple:
A tuple is an ordered collection of fields. - Bag:
A tuple bag is a collection of tuples. - Map:
A map is a collection of key/value pairs.
