By reducing the redundant data, normalization is a rigorous procedure that enhances data integrity in the table. There are various procedures involved in converting the data into tabular form and eliminating data redundancy from relational tables. Additionally, it gets rid of unwanted traits like Insertion, Update, and Deletion Anomalies.
- When we are unable to put data into the table without another attribute already existing, this is known as an insertion anomaly.
- Update irregularity: An update anomaly is a data discrepancy brought on by an incomplete update and data redundancy.
- A deletion anomaly is a phenomena that occurs when some traits are lost as a result of the loss of other features.
There are 7 normal forms including the Boyce code normal form, out of which 3 are the forms/processes widely used.

First, let’s consider an example of raw data prior to normalization.
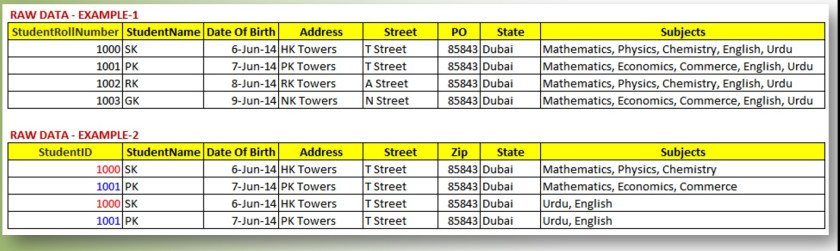
Let’s talk about anomalies-
In Example 2, if you need to change a student’s address, you must do so in every row where the StudentName was redundant. The data won’t be consistent otherwise. Update anomaly, that is.
If a new student enrols but hasn’t chosen a group yet, we must insert NULL into the subjects field, which causes an Insertion Anomaly.
We must erase the entire row along with the student information if the student initially chose MEC (a group in India’s 10+1 and 10+2) and later changed to HEC (another group). This is a deletion anomaly.
So let’s see what “first normal form” does.
First Normal Form:
A table is said to be in its First Normal Form if its atomicity is 1. A single cell can only carry one value in this case due to the concept of atomicity. There can be just one attribute with it. In other words, both composite attributes and multi-valued attributes, as well as their combinations, are forbidden by the First Normal Form.
The data shown in the previous image received the following modification after adhering to the first normal form.
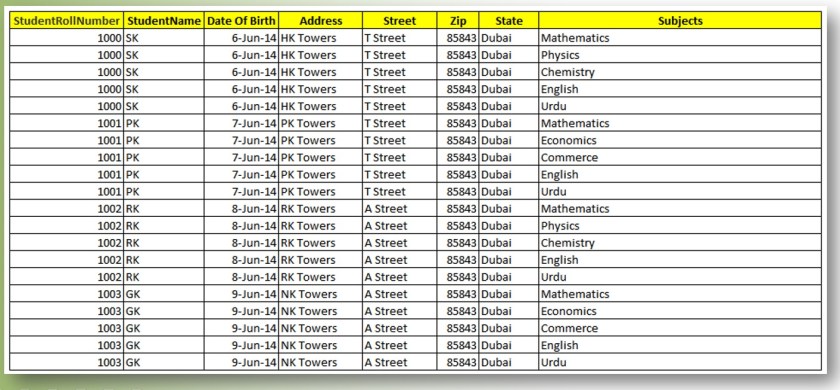
You must ensure that no table contains several columns that you may utilize to obtain the same information in order to attain the first normal form for a database. Each row in a table should have a primary key that identifies it as distinct, and each row should be arranged into columns. The primary key is typically a single column, but it is occasionally possible to combine many columns into a single primary key. Even though each row will be distinct, there may be duplicate data across several rows when using the initial normal form criteria.
Second Normal Form:
The table must first be in First Normal Form in order for it to be in Second Normal Form. There shouldn’t be any partial dependencies in the table. The proper subset of the candidate key should produce a non-prime attribute because of the partial reliance in this situation. In other words, a single-column primary key that does not functionally dependent on any subset of candidate key relation.
According to the 2NF, no column may be partially dependent on the primary key. Look at the table in 1NF above. Since each student selected a group of subjects, there are many rows for each of them. It is a waste of space even though it is searchable and adheres to the first normal form. Additionally, the topic is not about the student’s personal information, but rather his education. As a result, we segregate the subjects into different tables and ensure that they are linked together by a key (or with Student Name). It will then become 2NF.
The data shown in the previous image received the following modification after adhering to the second normal form. The data revolves around “StudentName” hence that column was considered a primary key in this example. In real-time, usually, it is preferable to have a numbered column as a primary key.

Third Normal Form:
The first requirement is the table has to be in 2NF before proceeding to 3NF.
Non-prime attributes that are not a part of the candidate key should not depend on other non-prime characteristics in a table, according to the second requirement, which states that there should be no transitive reliance on non-prime attributes.
As a result, a transitive dependency is a functional dependency in which A determines C indirectly due to A B and B C (where B A is not true).
Now, when you look above and see the same subjects, groups, and names, you know there is some uncertainty. The third normal form suggests making sure that each non-key element in each table has details about the row’s key. It is useful to add a distinct primary key that sets each subject apart from the others in order to establish an unambiguous unique identification for each subject. For improved efficiency, it is preferable to search using the keys rather than text when retrieving data from a table. Additionally, the text will occupy more space than keys.
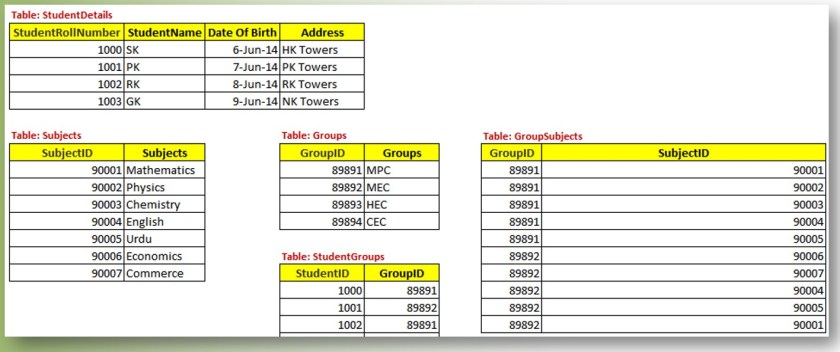
The sample data has been divided so as to lessen repetition and to segregate the data according to its nature. Additionally, the essential properties of the tables are related to one another.
Hope you find this article helpful.
Please subscribe for more interesting updates.

2 comments