This blog aims to provide practical knowledge on Apache Hive’s input file formats. After reading this article, you would have a clearer idea of how to work with various file formats. For theoretical knowledge, please read my previous article “File Formats and Compression in Apache Hive“.
HiveQL handles structured data only, much like SQL. In order to store the data in it, Hive has a derby database by default. The data will be stored as files in the backend framework while it shows the data in a structured format when it is retrieved. File format is a way of storing the data with compression codecs in the backend. The file formats that Hive can handle are: Text file format, Sequence File Format, RC (Row Column) File Format, Avro, Parquet, ORC File Format and Custom Input and Output Format.
Let’s start with “Text File Format“.
Hive Text file format is a default storage format to load data from comma-separated values (CSV), tab-delimited, space-delimited, or text files that delimited by other special characters. You can use the text format to interchange the data with other client applications. The text file format is very common for most of the applications. Data is stored in lines, with each line being a record. Each line is terminated by a newline character (\n). The text file format storage option is defined by specifying “STORED AS TEXTFILE” at the end of the table creation.
Consider the below dataset:
Filename: book.csv
BookID, BookName
2124, Don Quixote. By Miguel de Cervantes.
2134, Lord of the Rings. By J.R.R. Tolkien.
2135, Harry Potter and the Sorcerer’s Stone. By J.K. Rowling.
2136, And Then There Were None. By Agatha Christie.
2138, Alice’s Adventures in Wonderland. By Lewis Carroll.
2139, The Lion, the Witch, and the Wardrobe. By C.S. Lewis.
2141, Pinocchio. By Carlo Collodi.
2147, Catcher in the Rye.
2148, Don Quixote. By Miguel de Cervantes.
The file is copied on the Desktop, that means Cloudera’s local file system.
CREATE TABLE Books (
BookID INT,
BookName STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘,’
STORED AS TEXTFILE;
Please note that ‘STORED AS TEXTFILE’ is optional because Hive stores the data in TEXT FILE format by default.
Now, load the data into the table.
LOAD DATA LOCAL INPATH ‘Desktop/book.csv’ INTO TABLE books;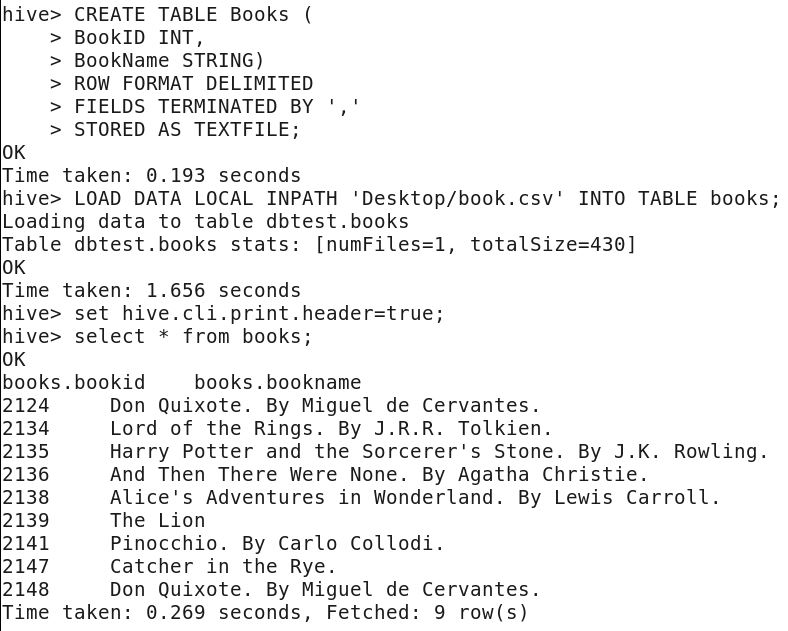
Now, let’s check where the table’s data is placed. Use Hue file browser to identify the data location. The table is created inside dbTest database which is in Hive warehouse.
The full-path in Cloudera VM will be “/user/hive/warehouse/dbtest.db/book.csv”

As you see the data is saved in a text file format.
Hope you find this article helpful.
Please do subscribe for more interesting updates.

4 comments