Before reading the below article, first read File Formats and Compression in Apache Hive & Exploring Input File Formats – Part-1. It’s a follow-up post to them.
We’ll look at the “Sequence File Format” in this session, which stores data in binary key-value pairs. Let’s take a look at “Sequence Files” and what they can accomplish for us.
When we deal with a small number of large files rather than a big number of little ones, Hadoop’s performance increases. A file is considered small if its size is smaller than the average block size in Hadoop. As a result, the NameNode will have to deal with an increase of metadata; In other words a overhead to NameNode. Sequence files were introduced in this case to serve as a container for the little files.
Consider the below dataset:
Filename: book.csv
BookID, BookName
2124, Don Quixote. By Miguel de Cervantes.
2134, Lord of the Rings. By J.R.R. Tolkien.
2135, Harry Potter and the Sorcerer’s Stone. By J.K. Rowling.
2136, And Then There Were None. By Agatha Christie.
2138, Alice’s Adventures in Wonderland. By Lewis Carroll.
2139, The Lion, the Witch, and the Wardrobe. By C.S. Lewis.
2141, Pinocchio. By Carlo Collodi.
2147, Catcher in the Rye.
2148, Don Quixote. By Miguel de Cervantes.
Loading data into this table differs from loading data into a table generated in TEX format. Because this SEQUENCEFILE format is binary, you must enter data from another table. It compresses the data before storing it in the table. We are unable to enter compressed files into tables, hence loading straight as in TEXTFILE format is not feasible. As a result, we must create a table in which the data is stored in TEXTFILE FORMAT. Once the data has been imported, we can extract and then use it to INSERT into the table that has been configured to save the data in SEQUENCE FILE FORMAT.
CREATE TABLE Books (
BookID INT,
BookName STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘,’
STORED AS TEXTFILE;
The above table can be treated as a staging table or a temporary table.
Now, load the data into the table.
LOAD DATA LOCAL INPATH ‘Desktop/book.csv’ INTO TABLE books;

Now, we have the data ready in our temporary table. Let’s create the table with SEQUENCE FILE FORMAT.
CREATE TABLE Books_Seq (
BookID INT,
BookName STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘,’
STORED AS SEQUENCEFILE;
–Loading the data
INSERT INTO Books_Seq
SELECT * FROM Books;

If you want to avoid this two step implementation (CREATE TABLE and INSERT INTO), you can simply use CTAS as given below.
CREATE TABLE books_seq STORED AS SEQUENCEFILE
AS SELECT * FROM books;
This will create the table and load the data in a single execution.
Now, let’s check the data in the backend, using Hue file browser, it should be in compressed format.
Have a look.
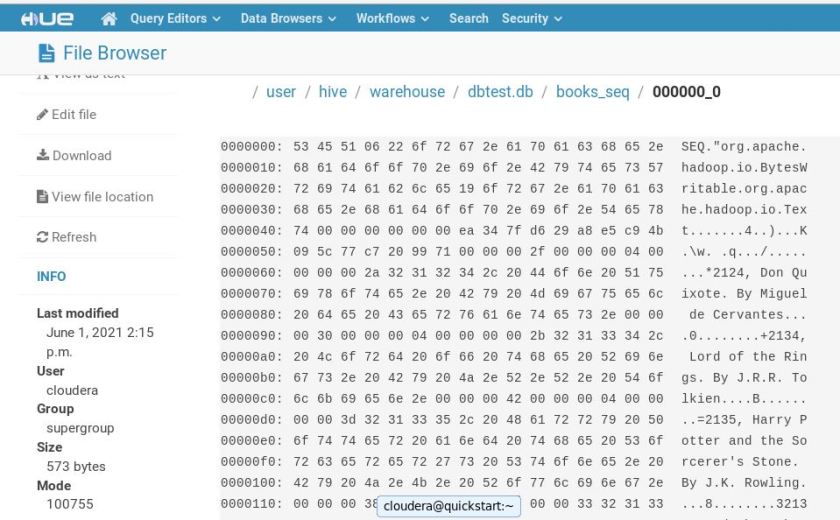
Hope you find this article helpful.
Please do subscribe for more interesting updates.

3 comments