There are numerous websites, as well as official documents, that explain Hadoop, its architecture, components, and so on. In this post, I’m attempting to summarize the points in such a way that novices and enthusiasts who don’t want to read through so many pages or chapters will be able to grasp them.
What is Big Data?
In modern digital era, data is created from a variety of sources, including mobile apps, sensors, CC cameras, social networks, online commerce, airlines, hospitality data, and so on. According to the study, 90% of the data generated in the previous few years. Take a look at the slides below to get an idea of the data volume.
Image Source: Web
According to a research published in 2015, 2.5 exabytes (2.5 Quintillon Bytes) of data being generated every day around the world. On an average 50,000 GB data per second.
The definition:
Big data is defined as data with increased variety, arriving in increasing volumes, with incredible velocity, a high degree of variability, and veracity, all of which must be processed in order to visualize and extract value from it.
The Problem:
Traditional data processing systems will be unable to store and process the vast volumes of data created every day from a number of data sources in a variety of formats in a cost-effective manner. It will be difficult and costly to scale-up the server’s and storage capacity every now and then.
In summary, the problem is storing and analyzing large amounts of data.
The Solution:
“If one person can finish a task in ten hours, how long will it take ten people to complete it?”
I hope you recall this arithmetic problem from your school days. The workload will be reduced and the outcome will be quicker if the work is dispersed. This was the solution used to deal with large amounts of data.
Rather than relying on a single server, the data will be distributed and processed among several machines. This leaves us to understand – If a machine with four I/O channels and a processing speed of 100 MB completes a work in 45 minutes, ten equivalent machines will finish in 4.5 minutes. This solution’s name is – Hadoop.
Hadoop:
Hadoop is an open-source software program that allows you to store and analyze massive quantities of data on inexpensive hardware clusters.
Another definition is – Apache Hadoop is a collection of open-source software tools for dealing with huge amounts of data and processing on a distributed network of computers. It’s a software framework for storing and analyzing large amounts of data in a distributed manner.
It is made up of two main components: HDFS and MapReduce. HDFS is in charge of storing large amounts of data across several nodes, whereas MapReduce is in charge of splitting the processing work over multiple processors.
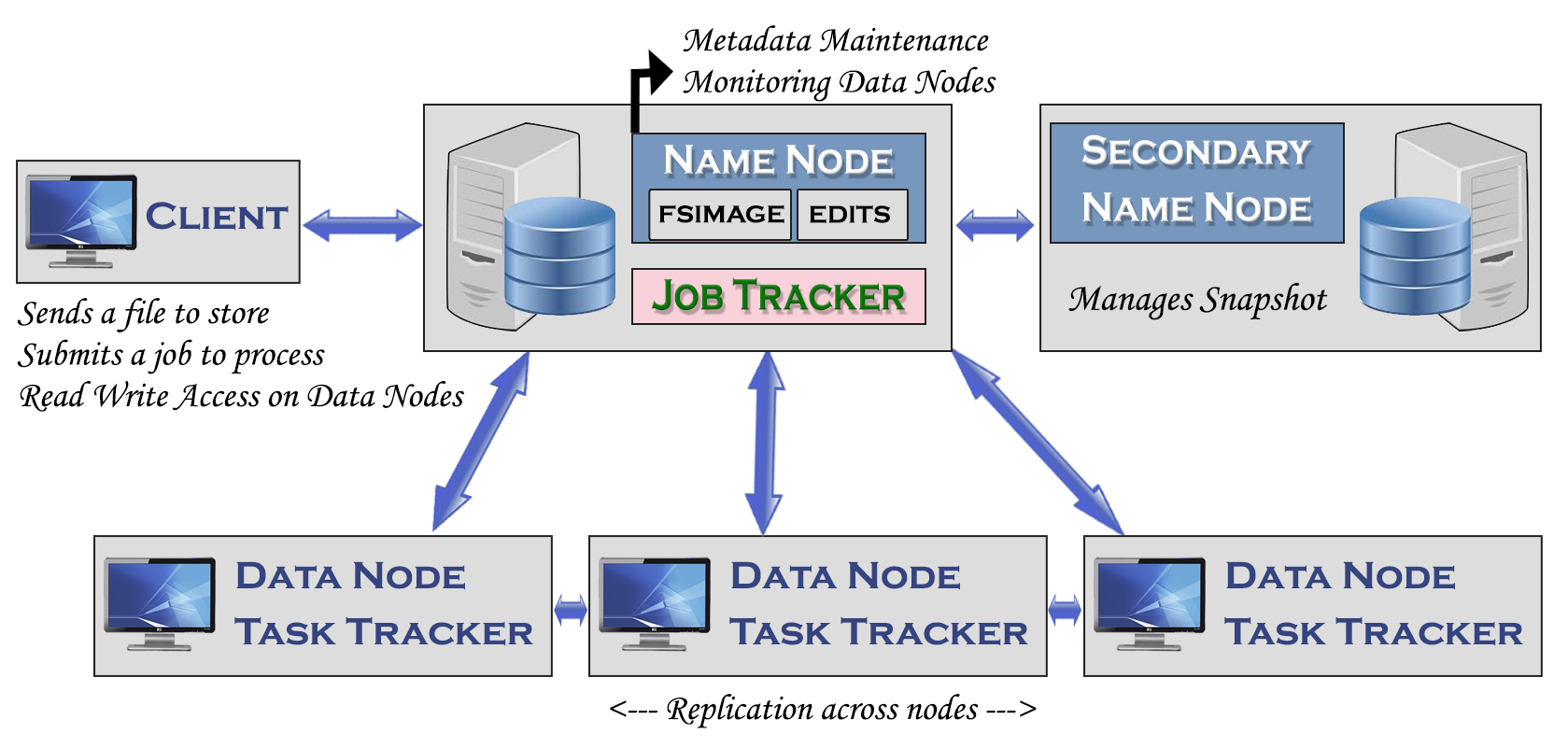
The Five Daemons:
HDFS and MapReduce are managed by five daemons (Services), each of which operates in its own Java virtual machine. Name Node (HDFS), Secondary Name Node (HDFS), Data Node (HDFS), Job Tracker (MapReduce), and Task Tracker (MapReduce) are the different types of services. The following are some significant points.
- HDFS is a distributed file system, and each machine is referred to as a Data-Node.
- HDFS is scalable in that it can handle any number of data nodes and is flexible in that it can store any amount and kind of data. Since Hadoop is open source and commodity hardware may be used, it is cost economical. It’s also fault tolerant, as the data is replicated three times by default.
- Hadoop changes the OS’s default behavior and increases the block size from 4KB to 64 MB in Hadoop version 1 and 128 MB in Hadoop version 2.
- Data nodes are organized into racks, and racks are organized into cluster, with only one Name node per cluster. Similarly, there is only one Job Tracker per cluster.
- The Name node’s job is to keep track of the metadata and monitor all of the Data nodes in the cluster.
- Data-node will transmit acknowledgement to Name-node every 3 seconds, which is referred to as heart-beat.
- Job tracker maintains a heartbeat with Task Trackers. The client submits a request, and Job tracker schedules/assigns the job to Task Tracker. Failed tasks are handled by re-execution. If a Task Tracker node fails, all tasks scheduled on it are re-executed on another node.
- Name node and Job Tracker along with Secondary Name node are called master services. Data node and Task trackers called slave services.
- The Task tracker will not interact with the Name node, and the Job tracker will not connect with the Data node. Except for that, all services will communicate with one another.

Image Source: Web
- By verifying the maximum available space, the name node will determine which node is the best choice for storing the file.
- Secondary name node isn’t a typical backup option. However, it aids in the backup of Name node metadata, which might be useful in the event of Name node failure or rebuild.
- Hadoop daemons run in three modes. (1) Standalone or local mode in which everything runs in a single JVM with no daemons. (2) Pseudo mode, in which Hadoop daemons run in local machine (3) Fully distributed mode, in which Hadoop daemons run in a cluster of machines.
- The Task tracker’s job is to read blocks from the Data node and execute mapreduce programs.
- The job tracker splits work based on where the data is stored: it tries to schedule map tasks on the same machine as the physical data.
The process work-flow of these five daemons are illustrated below.
I hope you found this post to be informative.
Please join our mailing list to receive more interesting information.

2 comments