Big Data definition:
Big data is defined as data with increased variety, arriving in increasing volumes, with incredible velocity, a high degree of variability, and veracity, all of which must be processed in order to visualize and extract value from it.
The Problem:
Traditional data processing systems will be unable to store and process the vast volumes of data created every day from a number of data sources in a variety of formats in a cost-effective manner. It will be difficult and costly to scale up the server’s storage capacity every now and then.
In summary, the problem is storing and analyzing large amounts of data.
The Solution:
“If one person can finish a task in ten hours, how long will it take ten people to complete it?”
I hope you recall this arithmetic problem from your school days. The workload will be reduced and the outcome will be quicker if the work is dispersed. This was the solution used to deal with large amounts of data.
Rather than relying on a single server, the data will be distributed and processed among several machines. This leaves us to understand – If a machine with four I/O channels and a processing speed of 100 MB completes a work in 45 minutes, ten equivalent machines will finish in 4.5 minutes. This solution’s name is – Hadoop.
Hadoop:
Hadoop is an open-source software program that allows you to store and analyze massive quantities of data on inexpensive hardware clusters.
Another definition is – Apache Hadoop is a collection of open-source software tools for dealing with huge amounts of data and processing on a distributed network of computers. It’s a software framework for storing and analyzing large amounts of data in a distributed manner.
It is made up of two main components: HDFS and MapReduce. HDFS is in charge of storing large amounts of data across several nodes, whereas MapReduce is in charge of splitting the processing work over multiple processors.
The below is an overview of how HDFS and MapReduce works.
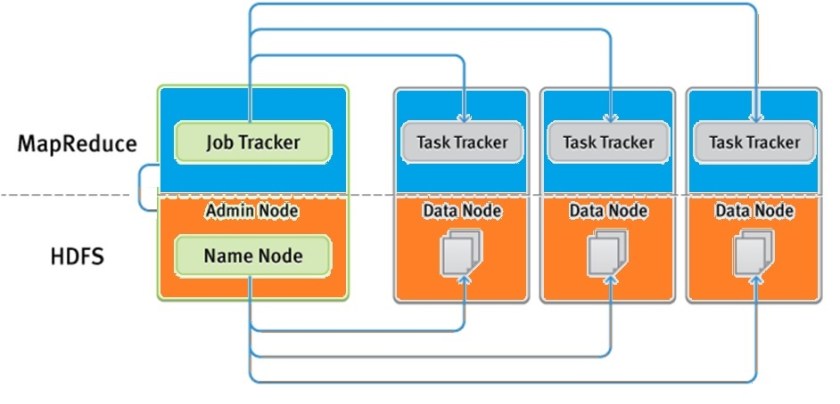
You can see the key elements of both HDFS and Map Reduce in the diagram below.

This post goes into more detail about Map Reduce and the processing components it uses. Please refer to Big Data – Explained for further information.
Job Tracker:
A daemon called JobTracker utilizes the MapReduce functionality of Apache Hadoop. It is a crucial service that distributes all MapReduce tasks among the cluster’s nodes.
In other words, JobTracker is in charge of assigning execution commands to the operator component that is present in each node and scheduling jobs. Rerunning unsuccessful jobs is another duty of it.
Task Tracker:
A TaskTracker is a node in the cluster that accepts tasks from a JobTracker, including Map, Reduce, and Shuffle operations. Each TaskTracker has a set of slots preset, which represent the maximum number of tasks it can receive.
- DataNode is used to execute TaskTracker on almost on every DataNode.
- Mapper and Reducer tasks will be delegated to TaskTrackers by JobTracker for execution.
- The execution of the task will be tracked by TaskTracker and reported in real time to JobTracker.
Failure of TaskTracker is not regarded as fatal. The task carried out by a TaskTracker will be delegated to another node by JobTracker if the TaskTracker stops responding.
In simple words, Task Tracker exists on each node and executes instructions and relays feedback back to the controller component.
The functioning of MapReduce occurs in two phases: the map phase and the reduce phase.
Mapping or Map Phase:
This is the initial stage of a processing task’s execution in the Hadoop system. The input data must be pre-processed to fit the required format because the framework only recognizes data in pairs. Through logical splitting process, the incoming dataset is divided into more manageable portions.
The available mappers are then given the logical chunks, and they divide each input record into pairs. This phase’s output is regarded as intermediate output. Before being sent into the reducers, the output of the mapper may go through a preliminary processing step. Combining, sorting, partitioning, and shuffling are some of the procedures.
The intermediate data from these operations is stored in the corresponding processing node’s local file system.

One comment